More Twitter Account Graphs
By: Jeff Clark Date: Thu, 28 May 2009
Here is another graph showing a larger set of twitter accounts and their relationships based on a measure of shared vocabulary. The middle left cluster contains many Twitter accounts who discuss web technology including Twitter itself. I'm familiar with many of these accounts and know that the ones around my own icon ( JeffClark ) discuss data visualization (eagereyes, flowingdata, datavis, infosthetics). At the bottom right is a cluster of accounts that I follow which are focused on computational art (blprnt, flight404, toxi, mariuswatz, golan, reas, natzke). The group at the very top contains accounts with an interest in music or entertainment.
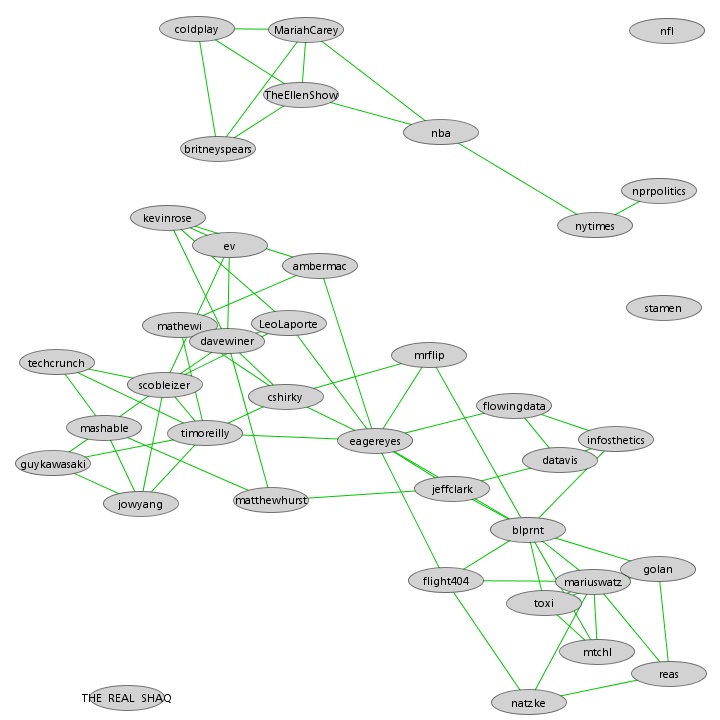
To create this graph I'm connecting nodes with a virtual spring if their similarity was greater than 9%. The stronger the similarity the shorter the spring. There are also long springs connecting extremely dissimilar nodes to push them apart but these are not shown. I've tried to avoid the usual tangled mess by not connecting nodes of medium similarity and also by only connecting two nodes if the link is one of the three strongest for either node.